Enyakın komşu (nearest neighbor): En yakın komşu algoritmaları şu probleme çözüm arar: Bir X metrik uzayında, n veri noktalarının S kümesi verilir ve bu noktalar önceden işlenerek, verilen herhangi bir X uzayındaki q sorgu noktasının q’ya en yakın veri noktası hızlı bir şekilde raporlanabilmesidir. Bu aynı zamanda en yakın nokta sorunu ve postane sorunu olarak da adlandırılır [1]. En yakın komşu bulma problemi, görüntü tanıma, örüntü bulma, veri madenciliği, makine öğrenmesi, veri sıkıştırma, istatistik vb. çeşitli uygulamalarda sıklıkla kullanılan bir problemdir.
Bu yöntem denetimli öğrenme yöntemleri içerisinde etkili sınıflandırma algoritmalarından bir tanesidir. Öğrenme kümesi içerisinde bulunan normal davranış benzerlikleri hesaplanarak, en yakın görülen “k” verinin ortalamasının oluşturduğu eşik değerine göre sınıflandırma işlemi gerçekleştirilir. Burada sınıflandırma işlemi için öncelikle, sınıf özelliklerinin belirlenmiş olması gerekmektedir. Ayrıca “k” komşu sayısı, benzerlik ölçümü, eşik değeri ve öğrenme kümesindeki normal davranışların yeterliliği, bu yöntemin performansını etkileyen faktörlerdendir [2].
Basit bir yapıda olmasına rağmen özellikle büyük eğitim kümeleri için uzaklık-yakınlık belirleme işlemi maliyetli olabilmektedir. Bundan kaçınmak için bu algoritmada boyut azaltma yöntemi uygulanabilir veya arama ağaçları gibi daha güçlü veri yapıları ile birlikte kullanılabilir [3].

K en yakın komşu algoritmasının performansı için önemli parametreler komşu sayısı “k”, ağırlıklandırma yöntemi ve uzaklık ölçütüdür. Başlıca uzaklık ölçütleri olarak, Minkowski, Öklid ve Manhattan, uzaklıklarından bahsedilebilir. Denklemlerde x ve y iki farklı noktayı ifade etmektedir. Minkowski uzaklığında, farklı q değerleri için çeşitli uzaklık ölçütleri tanımlanabilir.
Naive bayes sınıflandırıcı: Naive Bayes bir olasılık sınıflandırıcı algoritmasıdır. Bu algoritmada veri içerisinde bulunan değerlerin frekansları ve bunların aralarındaki kombinasyonlar sayılarak bir olasılık kümesi oluşturulur [4]. Algoritma matematikçi Thomas Bayes teoremini kullanır ve sınıf değişkeninin değeri göz önüne alındığında tüm değişkenlerin bağımsız olduğunu varsayar.

Denklemde 𝑑 bilinen durum, 𝑐𝑗 ise farklı koşullu durumları ifade etmektedir. Naive Bayes teoremi, avantaj ve dezavantajları olarak şu özelliklere sahiptir [5]:
 |
| Naive Bayes teoremi avantaj ve dezavantajları |
Karar ağaçları (decision trees): Bir sınıflandırma ağacı, bir nesnenin sınıfını yordayıcı değişkenlerin değerlerinden tahmin etmek için deneysel bir kuraldır [6]. Tahminsel bir model olup ağaç yapısında ilerlediğinden bu isim verilmiştir. Ağacın dalları ve yaprakları, sınıflandırma probleminin çözümünü içeren parçalardır. Karar ağaçları avantaj ve dezavantajları olarak aşağıdaki özelliklere sahiptir [7–8].
 |
| Karar ağaçlarının avantaj ve dezavantajları |
Karar ağacı oluşturmak için geliştirilen algoritmalar arasında şunlar sayılabilir [9–11]:
- CHAID (Chi- Squared Automatic Interaction Detector),
- C4.5,
- C5.0,
- CRT (Classification and Regression Trees),
- Exhaustive CHAID,
- ID3,
- MARS (Multivariate Adaptive Regression Splines),
- QUEST (Quick, Unbiased, Efficient Statistical Tree),
- SLIQ (Supervised Learning in Quest),
- SPRINT (Scalable Paralleizable Induction of Decision Trees)
Doğrusal regresyon (linear regression): Regresyon analizi istatistiksel bir tekniktir ve değişkenler arasındaki ilişkiyi araştırıp modellemek için kullanılır. [12]. Bu teknikte tahmin edilmeye çalışılan “Y” değişkeni ile tahminleyici “X1, X2, …, Xn” değişkenler arasında bir ilişki olduğu varsayılır. Doğrusal regresyon analizi basit ve çoklu doğrusal regresyon olmak üzere ikiye ayrılır [13].
Basit ve çoklu doğrusallığı, yanıt değişkeni ile açıklayıcı değişken arasındaki ilişki açıklamaktadır. Bu ilişkide tek bir açıklayıcı değişken varsa basit regresyon, birden fazla açıklayıcı değişken varsa çoklu regresyon analizi kullanılabilir [14–15]. Basit ve Çoklu regresyon için şu eşitlikler kullanılmaktadır [16].
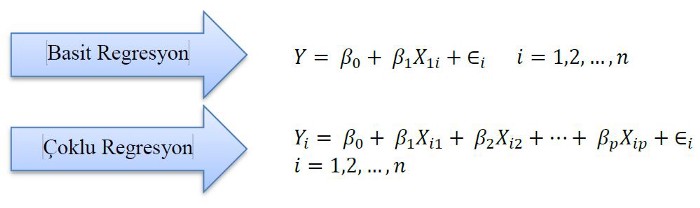
Destek vektör makineleri (support vector machines-SVM): Doğrusal ve doğrusal olamayan veriler için sınıflandırma yapabilen özellikle sınıflandırma ve regresyon için kullanılan bir algoritmadır [17–18]. 1979 yılında Vapnik ve Lerner tarafından tanıtılan SVM, kısıtlı durumlarda eğitim verilerine hatasız olarak uygulanabilirken, Cortes ve Vapnik 1995 yılında ayrılmayan eğitim verilerine de uygulanarak genişletilmiştir[19]. SVM hedef verileri sınıflandıran en uygun ayırma hiper düzlemini bulmaya odaklanır. Doğrusal ve doğrusal olmayan iki tipik varyasyonu kullanarak regresyon ve sınıflandırma problemlerini ele alır [20].
SVM ile ampirik risk minimizasyonu prensibine göre değil de, istatistiksel öğrenme teorisindeki yapısal risk minimizasyonu niteliğinde çalışılır [21]. Basit Regresyon Çoklu Regresyon SVM’de temel olarak eğitim kümesindeki örneklerin bağımsız ve benzer olarak dağıtıldığı varsayılır [22].
SVM, problemlerin çözümüne ulaşmak için çekirdek fonksiyonlarını kullanır. Sıklıkla kullanılan çekirdek fonksiyonları şöyledir [23]:


Yapay sinir ağları (artificial neural networks): Yapay sinir ağları (YSA), değişen ağırlıklarda bağlantılarla birbirine bağlanan ve her biri kendi belleğine sahip işlem elemanlarından oluşan, insan beyninden esinlenerek geliştirilen bilgi işleme yapılarıdır.

Şekilde görüldüğü gibi YSA, kendisine verilen girdiye ağırlıklar ve aktivasyon fonksiyonunu kullanarak bir çıktı üretmektedir.
Sinir hücreleri, girdi katmanı, ara katmanlar ile çıktı katmanı olmak üzere 3 katman halinde ve her katman içinde paralel olarak bir araya gelir ve ağı oluştururlar. Bu katmanlar [25]:
- Girdi katmanı: İşlem elemanlarının dışarıdan alınarak ara katmanlara transfer edildiği, bilgi işlemenin gerçekleştirilmediği katmandır.
- Ara katmanlar: Girdi katmanından gelen bilgilerin işlendiği katmanlardır ve birden fazla olabilirler.
- Çıktı katmanı: Ara katmandan gelen bilgi işlenir ve girdi için üretilen çıktı dışarıya gönderilir.
Yapay sinir ağları, öğrenme ve genelleme, veriye uyum, paralel çalışabilme, doğrusal olmama, hata toleransı gibi çeşitli üstünlüklere sahiptir. Mühendislik, tıp, finans, endüstri vb. gibi pek çok uygulama alanlarında kullanım örnekleri de mevcuttur [26].
Denetimsiz öğrenme modelleri bir sonraki postta…
KAYNAKLAR
[1] Arya, S., Mount, D. M., Netanyahu, N. S., Silverman, R., and Wu, A. Y. (1998). An optimal algorithm for approximate nearest neighbor searching fixed dimensions. Journal of the ACM, 891–923.
[2] Kırmızıgül Çalışkan, S., ve Soğukpınar, İ. (2008). KxKNN: K-Means ve K En Yakın Komşu Yöntemleri İle Ağlarda Nüfuz Tespiti. EMO Yayınları, 120–124.
[3] Taşcı, E., ve Onan, A. (2016). K-En Yakın Komşu Algoritması Parametrelerinin Sınıflandırma Performansı Üzerine Etkisinin İncelenmesi, 102. Aydın: XVIII. Akademik Bilişim Konferansı — AB 2016.
[4] Patil, T. R., and Sherekar, S. S. (2013). Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification. International Journal Of Computer Science And Applications, 256–261.
[5] Saharkhiz, A. (2009). Naive Bayes Theorem. Web: https://www.codeproject.com/Articles/33722/Naive-Bayes-Theorem
[6] SPSS. (1999). AnswerTree Algorithm Summary. Web: https://s2.smu.edu/~mhd/8331f03/AT.pdf
[7] Pehlivan, G. (2006). Chaid analizi ve bir uygulama, Yüksek Lisans Tezi, Yıldız Teknik Üniversitesi Fen Bilimleri Enstitüsü, İstanbul.
[8] BÜ. (2019). Karar Ağacı (Decision Karar Ağacı (Decision tree) nedir? Başkent Üniversitesi, Web: http://mail.baskent.edu.tr/~20410964/DM_8.pdf
[9] Albayrak, A. S., ve Koltan Yılmaz, Ş. (2009). Veri Madenciliği: Karar Ağacı Algoritmaları ve İMKB Verileri Üzerine Bir Uygulama. Süleyman Demirel Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi, 14(1), 31–52.
[10] Emel, G. G., ve Taşkın, Ç. (2005). Veri Madenciliğinde Karar Ağaçları ve Bir Satış Analizi Uygulaması. Eskişehir Osmangazi Üniversitesi Sosyal Bilimler Dergisi, 6(2), 221- 239.
[11] Uzgören, N., Kara, H., ve Uzgören, E. (2005). Yöneticilerde Boyun Eğici Davranış Eğilimlerinin CHAID Analizi ile İncelenmesi: Yönetici Adayı Öğrenciler Üzerine Bir Araştırma. EKEV Akademi Dergisi, 19(61), 429–440.
[12] Montgomery, D. C., Elizabeth, A., Peck, G., and Vining, G. (2012). Introduction to Linear Regression Analysis. New Jersey, USA.: John Wiley & Sons Inc.
[13] Arı, A., ve Önder, H. (2013). Farklı Veri Yapılarında Kullanılabilecek Regresyon Yöntemleri. Anadolu Tarım Bilimleri Dergisi, 28(3), 168–174.
[14] Okur, S. (2009). Parametrik Ve Parametrik Olmayan Doğrusal Regresyon Analiz Yöntemlerinin Karşılaştırmalı Olarak İncelenmesi, Yüksek Lisans Tezi, Çukurova Üniversitesi Fen Bilimleri Enstitüsü, Adana.
[15] Weisberg, S. (2005). Applied Linear Regression. New Jersey: John Wiley & Sons Inc.
[16] Kutner, M. H., Nachtsheim, C. J., Neter, J., and Li, W. (2005). Applied Linear StatisticalModels. New York: McGraw-Hill Irwin Companies Inc.
[17] Çomak, E., Arslan, A., ve Türkoğlu, İ. (2007). A decision support system based on support vector machines for diagnosis of the heart valve diseases. Computers in Biology and Medicine, 37(1), 21–27. doi: 10.1016/j.compbiomed.2005.11.002
[18] Santhanam, T., and Padmavathi, M. S. (2015). Application of K-Means and Genetic Algorithms for Dimension Reduction by Integrating SVM for Diabetes Diagnosis. Procedia Computer Science, 47, 76–83. doi: 10.1016/j.procs.2015.03.185
[19] Cortes, C., and Vapnik, V. (1995). Support-Vector Networks. Machine Learning, 20(3), 273–297. doi: 10.1023/A:1022627411411
[20] Calp, M. H. (2018). Medical Diagnosis with a Novel SVM-CoDOA Based HybridApproach. BRAIN — Broad Research in Artificial Intelligence and Neuroscience, 9(4), 6–16.
[21] Yakut, E., Elmas, B., ve Yavuz, S. (2014). Yapay Sinir Ağları ve Destek Vektör Makineleri Yöntemleriyle Borsa Endeksi Tahmini. Süleyman Demirel Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi, 19(1), 139–157.
[22] Song, Q., Hu, W., and Xie, W. (2002). Robust Support Vector Machine with Bullet Hole Image Classification. IEEE Transactions on Systems, Man, And Cybernetics — Part C: Applications And Reviews, 32(4), 440–448.
[23] Çankaya, Ş. F., Çankaya, İ. A., Yiğit, T., ve Koyun, A. (2018). Diabetes Diagnosis System Based on Support Vector Machines Trained by Vortex Optimization Algorithm. Nature-Inspired Intelligent Techniques for Solving Biomedical Engineering Problems, 203–218. doi: 10.4018/978–1–5225–4769–3.ch009
[24] Özkan, Y. (2008). Veri Madenciliği Yöntemleri. İstanbul: Papatya Yayınları.
[25] Öztemel, E. (2003). Yapay Sinir Ağları. İstanbul: Papatya Yayınları.
[26] Arı, A., ve Berberler, M. (2017). Yapay Sinir Ağları ile Tahmin ve Sınıflandırma Problemlerinin Çözümü İçin Arayüz Tasarımı. Acta Infologica, 1(2), 55–73.
[27] Savaş, S. (2019), Karotis Arter Intima Media Kalınlığının Derin Öğrenme ile Sınıflandırılması, Gazi Üniversitesi Fen Bilimleri Enstitüsü Bilgisayar Mühendisliği Ana Bilim Dalı, Doktora Tezi, Ankara.
Hiç yorum yok:
Yorum Gönder