It is very difficult to detect and access interesting and valuable information in large databases. Stages of Knowledge Discovery in Databases play a huge role in reaching this valuable, previously unknown, usable information by applying certain methods. The algorithm used to implement data mining enables us to realize the information discovery process in databases. In this process, it is necessary to know the properties of the data on which the model will be applied.
Data mining is also a process. In addition to uncovering the data by making abstract excavations between data stacks, separating and filtering patterns in the information discovery process and making them ready for the next step is also part of this process. If the properties of the work and data under investigation are unknown, it is not possible for any data mining algorithm to benefit, regardless of how effective it is. For this reason, before entering the data mining process, the first condition of success is a detailed analysis of job and data characteristics.
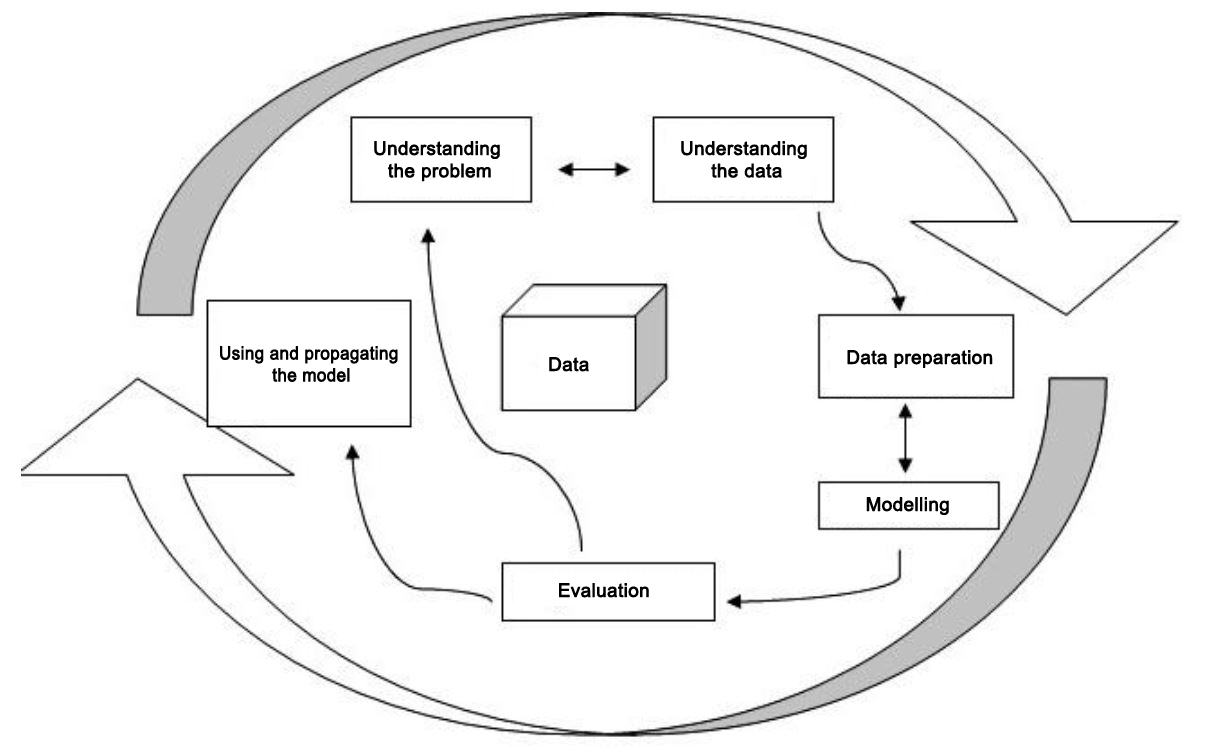
The steps followed in the data mining process are generally as follows [1]:
- Defining the problem,
- Preparation of data,
- Establishment and evaluation of the model,
- Using the model,
- Watching the model.
 |
| Data mining in the knowledge discovery process |
Defining the problem
The most important condition for success in data mining studies is to define the business purpose of the project and how the success levels of the results to be achieved will be measured. In addition, the costs to be incurred in incorrect estimates and estimates of the benefits to be gained in correct estimates should be included at this stage. At this stage, how the current business problem will be solved if the result is produced, the cost-benefit analysis of the result to be produced, in other words, the value of the produced information for the enterprise should be analyzed correctly.
This stage is the most important stage of the data mining process. The stage of defining the research problem (subject) includes the purpose of the research, the assessment of the current situation, the objectives of data mining and the determination of the project planning process.
Preparation of data
Problems that will arise during the establishment of the model will cause frequent return to this stage and rearrangement of the data. This causes an analyst to spend 50% -85% of his energy and time in the total data discovery process for the stages of data preparation and model establishment [2].
At this stage, it should not be forgotten that the numerical information produced by the company on the existing information systems should be analyzed well, and there should be a relationship between the data and the current business problem. With which business processes the digital data to be used within the scope of the project were created, it should be analyzed without using this data, so that the analyst can have an idea about the data quality.
Data quality is a key issue in data mining. To increase reliability in data mining, data pre-processing should be done. Otherwise, incorrect input data will lead the user to incorrect output. Data preprocessing is a data mining phase that is semi-automatic in most cases and takes time as mentioned above. The increase in the number of data and the necessity of preprocessing of a large number of data accordingly made effective techniques for automatic data preprocessing important [3].
Preparation of data consists of the following stages:
- Collection,
- Appraisal,
- Assembling and cleaning,
- Sample selection,
- Conversion.
Establishment and evaluation of the model
Finding the most suitable model for the defined problem is possible by installing and testing as many models as possible. For this reason, data preparation and model building stages are an iterative process until the best model is reached. The model establishment process differs according to the models in which supervised and unsupervised learning is used.
In supervised learning, which is also called learning from example, the relevant classes are separated according to a predetermined criteria by an auditor, and various examples are given for each class. The aim of the system is to find the features of each class based on the examples given and to express these features with rule sentences. When the learning process is completed, the defined rule sentences are applied to the given new examples and the class of the new examples is determined by the established model [4].
In unsupervised learning, as in cluster analysis, it is aimed to observe the relevant examples and to define the classes based on the similarities between the characteristics of these samples.
After the relevant data is prepared in accordance with the algorithm selected in supervised learning, in the first stage, part of the data is reserved for learning the model and the other part for testing the validity of the model. After learning the model using the learning set, the accuracy level of the model is determined with the test set [5].
The simplest method used to test the accuracy of a model is simple validity test. In this method, typically between 5% and 33% of the data is separated as test data, and after the learning of the model on the remaining part, the test is performed on these data. The error rate is calculated by dividing the number of events classified as false in a classification model by the number of all events, and the accuracy rate is calculated by dividing the number of correctly classified events by the number of events.
Another method that can be used in case of limited amount of data is cross validation test. In this method, the data set is randomly divided into two equal parts. In the first stage, model training on one part and testing on the other part, in the second stage, model training on the second part and the average of the error rates obtained by testing on the first part is used [5].
In small databases consisting of a few thousand rows or less, an n-fold cross validation test in which the data is divided into n groups may be preferred. In this method where data is divided into 10 groups, for example, the first group is used for testing and the other groups are used for learning. This process is continued by using one group for testing and the other groups for learning. The average of the ten error rates obtained as a result will be the estimated error rate of the established model.
Bootstrapping is another technique used to estimate the error level of the model for small data sets. As with cross validation, the model is built on the entire data set. Then, a large number of learning sets, at least 200, sometimes more than a thousand, are formed from the data set with repeated sampling and the error rate is calculated [6].
Before starting the model establishment studies, it is difficult to decide which technique is the most suitable. For this reason, it is useful to make countless trials to find the most suitable model according to their accuracy by establishing different models.
 |
| Risk matrix |
The risk matrix, which is a simple but useful tool, is used to evaluate the accuracy of the models established for classification problems. In this matrix shown on the side, there are actual classification values in the columns and estimated classification values in the rows. For example, it is easily seen in the matrix that 46 elements that should actually belong to class B are classified as 2 A, 38 as B, and 6 as C by the model established.
Another important evaluation criterion is the understandability of the model. While small increases in accuracy are very important in some applications, in many enterprise practice it may be even more important to be able to interpret why the decision was made. Although they are rarely too complex to be interpreted, decision trees and rule-based systems in general can very well reveal the underlying reasons for model estimation.
Leverage ratio and graph are an important aid in evaluating the benefit provided by a model. For example, in an application aimed at determining the customers who will probably return the credit card, if 35 of the 100 people determined by the model used actually return their credit card after a while and only 5 of the 100 randomly selected customers return their credit cards in the same time period, the leverage ratio will be found as 7 [7].
Another criterion used in determining the value of the established model is the rate of return of the investment to be obtained by dividing the income to be obtained from the application proposed by the model by the cost to be incurred for the implementation of this application.
No matter how high the accuracy of the installed model is, it is not possible to guarantee that it fully models the real world. The main reasons why a valid model is not correct as a result of the tests performed are the assumptions accepted in the model establishment and the incorrect data used in the model. For example, the change in the assumed inflation rate over time during the establishment of the model will significantly affect the purchasing behavior of the individual [5].
Using the model
The established and validated model can be a direct application or can be used as a sub-part of another application. Established models should create meaningful patterns and evaluations for problem solutions intended in the area of use.
Monitoring the model
Changes that occur in the properties of all systems and therefore in the data they produce will require continuous monitoring and rearrangement of established models. Graphs showing the difference between predicted and variables are a useful method for monitoring model results [3].
 |
| Data mining process steps |
REFERENCES
[1] Shearer, C., “The crisp-dm model: the new blueprint for data mining” Journal of Data Warehousing, 5(4), 13–23 (2000).
[2] Piramuthu, S., “Evaluating feature selection methods for learning in data mining applications”, Thirty-First Annual Hawai International Conference on System Sciences, Hawai, 5: 294 (1998).
[3] Kayaalp, K., “Asenkron motorlarda veri madenciliği ile hata tespiti”, Yüksek Lisans Tezi, Süleyman Demirel Üniversitesi Fen Bilimleri Enstitüsü, Isparta, 1–45 (2007).
[4] Akbulut, S., “Veri madenciliği teknikleri ile bir kozmetik markanın ayrılan müĢteri analizi ve müĢteri segmentasyonu”, Yüksek Lisans Tezi, Gazi Üniversitesi Fen Bilimleri Enstitüsü, Ankara, 1–25 (2006).
[5] Albayrak, M., “EEG sinyallerindeki epileptiform aktivitenin veri madenciliği süreci ile tespiti”, Doktora Tezi, Sakarya Üniversitesi Fen Bilimleri Enstitüsü, Sakarya, 56–70 (2008).
[6] Aldana, W.A., “Data mining industry: emerging trends and new opportunities”, Yüksek Lisans Tezi, Massachusetts Institute of Technology, Massachusetts, 11 (2000).
[7] İnan, O., “Veri madenciliği”, Yüksek Lisans Tezi, Selçuk Üniversitesi Fen Bilimleri Enstitüsü, Konya, 1–50 (2003).
Hiç yorum yok:
Yorum Gönder