Kendi kendine eğitim (self training): Yarı denetimli öğrenmede sıklıkla kullanılan bir tekniktir. Bu teknikte sınıflandırıcı öncelikle küçük boyutta bir etiketlenmiş veri ile eğitilir. Daha sonra bu sınıflandırıcı, etiketlenmemiş veri üzerinde kullanılarak sınıflandırma denenir. Tipik olarak en güvenli etiketlenmemiş noktalar, öngörülen etiketleriyle birlikte, eğitim setine eklenir. Bu işlem tekrar edilerek sınıflandırıcı eğitilmeye devam edilir [1].
Kendi kendine eğitim algoritması [2]:
L etiketli veri kümesi, U etiketlenmemiş veri seti iken;
TEKRAR:
- Bir h sınıflandırıcısı eğitim verilerini L ile eğit,
- U içerisindeki verileri h ile sınıflandır,
- En güvenli skorlara sahip bir U alt kümesi olan U’ kümesini bul,
- L + U’ → L
- U — U’ → U

Kendi kendine eğitim tekniğinin avantaj ve dezavantajları [3]
Üretken karışım modelleri (generative mixture models): En eski yarı denetimli öğrenme yöntemlerinden birisidir. Bir üretken modeli: P(x,y) = p(y)p(x|y) => burada p(x|y) tanımlanabilir bir karışım dağılımıdır. Örneğin Gaussian karışımı modelleri. Büyük miktarda etiketlenmemiş verilerle, karışım bileşenleri tanımlanabilir; o zaman ideal olarak karışım dağılımını tam olarak belirlemek için her bileşen için yalnızca bir etiketli örneğe ihtiyaç vardır. Karışım bileşenleri “yumuşak kümeler” olarak düşünülebilir. Bu yöntemde şunlara dikkat edilmelidir [1]:
- Tanımlanabilirlik,
- Model doğruluğu,
- Beklenti-maksimizasyonu,
- Küme ve etiket.
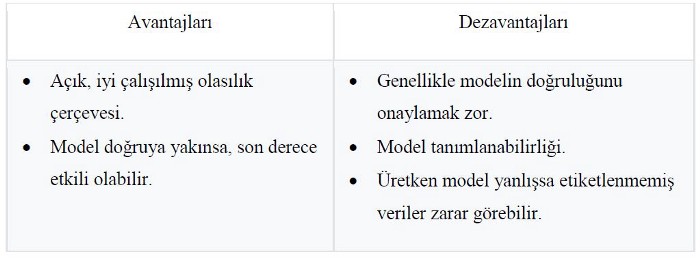
Üretken karışım modellerin avantaj ve dezavantajları [3]
Yarı denetimli destek vektör makinesi (semi-supervised support vector machine-S3VM): Yarı denetimli destek vektör makinesi, küme varsayımına dayanan yarı denetimli bir öğrenme yöntemi olarak Bennett ve Demiriz tarafından önerilmiştir [4]. S3VM’nin en temel amacı etiketli verileri ve etiketlenmemiş verileri kullanarak sınıflandırıcı oluşturmaktır. SVM fikrine benzer şekilde S3VM, etiketli verileri ve etiketlenmemiş verileri ayırmak için maksimum marjı gerektirir ve yeni optimal sınıflandırma sınırı, orijinal etiketlenmemiş verilerdeki sınıflandırmanın en küçük genelleme hatasına sahip olduğunu karşılamalıdır [5].
Yarı denetimli destek vektör makineleri, bazı sınıflandırma problemlerinde yaygın olarak kullanılabilir. Potansiyel uygulamalar görüntü sınıflandırma ve metin sınıflandırma olmakta ve bu iki konuda, yarı denetimli destek vektör makineleri iyi sonuçlar göstermektedir [5]. Yarı denetimli destek vektör makinesinin avantaj ve dezavantajları şunlardır [3]:
 |
| Yarı denetimli destek vektör makinesinin avantaj ve dezavantajları |
Grafik tabanlı algoritmalar (graph-based algorithms): Grafik tabanlı yarı denetimli yöntemler, düğümlerin veri kümesinde etiketli ve etiketsiz örnekleri gösterdiği ve kenarların (ağırlıklı olabilir) örneklerin benzerliğini yansıttığı bir grafiği tanımlar. Bu yöntemler genellikle grafik üzerinde etiket düzgünlüğü varsaymaktadır. Grafik yöntemleri parametrik olmayan, ayırt edici ve doğada transdüktiftir [1].
Grafik tabanlı yöntemlerde, her bir numunenin etiket bilgisi, tüm veri setinde global bir stabil duruma ulaşılana kadar komşu örneğine yayılır. Burada, düğümlerin etiketsiz ve etiketli örneklerle belirtildiği düğüm ve kenarlardan oluşan bir grafik oluşturulur, kenarlar etiketsiz ve etiketsiz örnekler arasındaki benzerlikleri belirtir. Burada her veri örneğinin etiketi, komşu noktalarına ilerletilir [6].
Grafik yapısı: G = (V, E) olarak yapılandırılır.
Burada:
V: etiketli ve etiketsiz veri örneklerini belirten bir dizi köşe,
E: etiketli ve veri setinden etiketlenmemiş örnekler arasındaki benzerlikleri gösteren bir kenar kümesidir [7].
 |
| Grafik tabanlı algoritmaların avantaj ve dezavantajları [3] |
Bazı grafik tabanlı yarı denetimli öğrenme algoritmaları şunlardır [3]:
- Harmonic,
- Local and global consistency,
- Manifold regularization,
- Mincut,
Çoklu görüntü algoritmaları (multiview algorithms): Aynı girdi verilerinin yedekli görünümlerinin talebi, çoklu görünüm ve tek görünüm öğrenme algoritmaları arasında büyük bir farktır. Bu çoklu görüntüler sayesinde, öğrenme görevi bol miktarda bilgi ile yapılabilir. Bununla birlikte, öğrenme metodu çoklu görüntülerle uygun şekilde başa çıkamıyorsa, bu görüntüler çoklu görüntülü öğrenmenin performansını düşürebilir [8].
Dünden Bugüne Yapay ZekaKAYNAKLAR
[1] Zhu, X. (2005). Semi-Supervised Learning Literature Survey. University of Wisconsin Madison Computer Sciences Department
[2] Xia, F. (2006). Semi-supervised learning and self-training. Web: http://faculty.washington.edu/fxia/courses/LING572/self-training.ppt
[3] Zhu, X. (2007). ICML. Semi-Supervised Learning Tutorial, 1–135. Madison, USA: University of Wisconsin Department of Computer Sciences.
[4] Bennett, K. P., and Demiriz, A. (1999). Advances in Neural Information Processing Systems (NIPS). Semi-supervised Support Vector Machines, 368–374. MIT Press.
[5] Ding, S., Zhu, Z., and Zhang, X. (2015). An overview on semi-supervised support vector machine. Neural Computing & Applications. doi: 10.1007/s00521–015–2113–7
[6] Sheikhpour, R., Sarram, M. A., Gharaghani, S., and ZareChahooki, M. A. (2017). A Survey on semi-supervised feature selection methods. Pattern Recognition, 141–158. doi: 10.1016/j.patcog.2016.11.003
[7] Sawant, S. S., and Prabukumar, M. (2018). A review on graph-based semi-supervised learning methods for hyperspectral image classification. The Egyptian Journal of Remote Sensing and Space Science. doi: 10.1016/j.ejrs.2018.11.001
[8] Xu, C., Tao, D., and Xu, C. (2013). A Survey on Multi-view Learning. 1–59. arXiv:1304.5634
[9] Savaş, S. (2019), Karotis Arter Intima Media Kalınlığının Derin Öğrenme ile Sınıflandırılması, Gazi Üniversitesi Fen Bilimleri Enstitüsü Bilgisayar Mühendisliği Ana Bilim Dalı, Doktora Tezi, Ankara.
Hiç yorum yok:
Yorum Gönder